Alternate title: I’m using AI to write code. Is it silly to use AI to review it?
I'm Daksh, a co-founder of Greptile. Our product uses AI to review pull requests to surface bugs and anti-patterns that humans might miss. Here is an example of what that looks like.
Recently, I was curious to see if there exists a power law in the number of PRs opened by individual Greptile users. In other words - were some users opening orders of magnitude more PRs than others? A quick SQL query later, I discovered that there is a power law to this.
I also noticed something else very interesting:
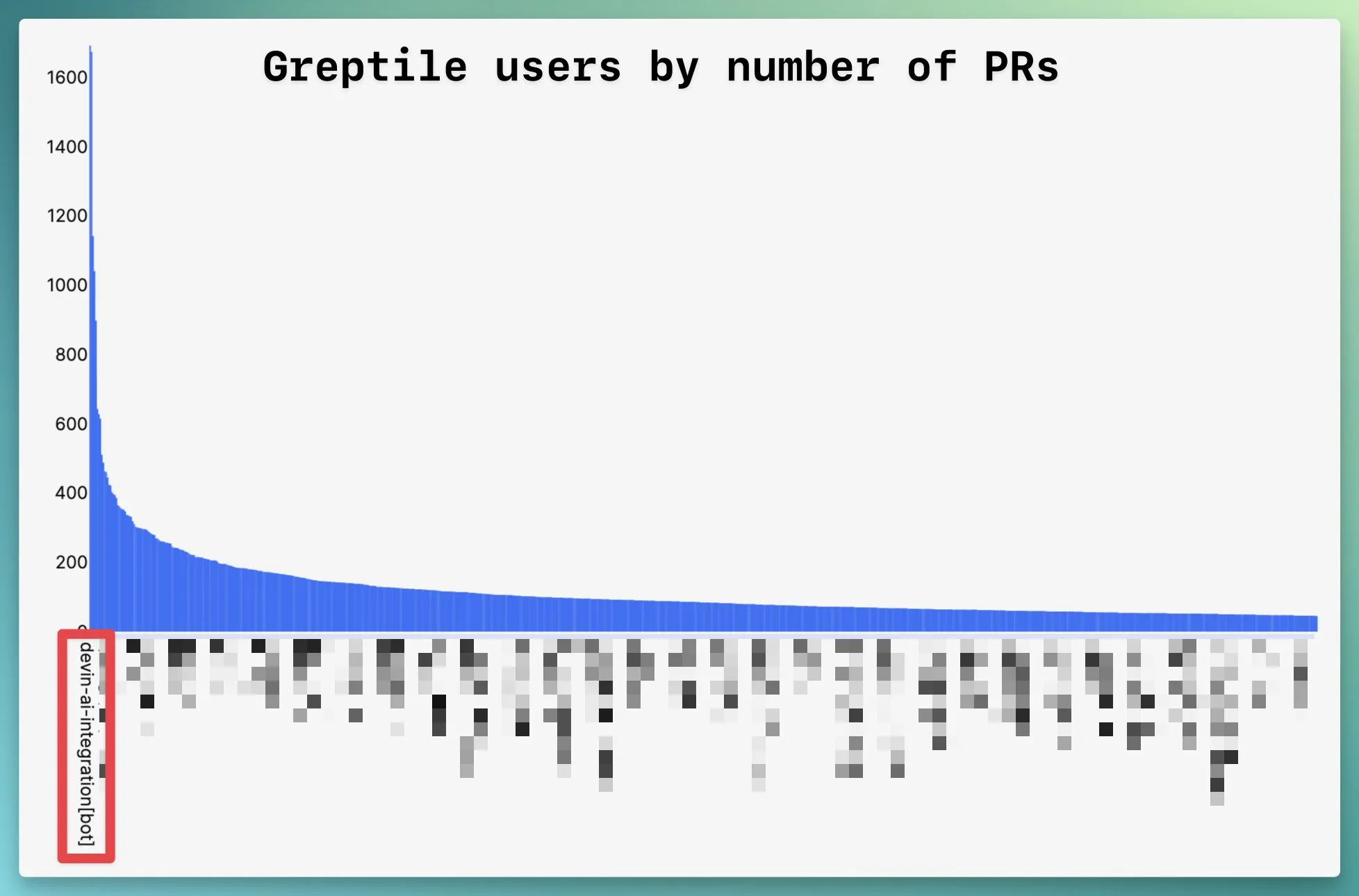
At the far left of the long list of GitHub usernames was “devin-ai-integration[bot]”. An AI bot was writing more pull requests than any individual human. [1]
Seeing as Devin uses the same LLMs under-the-hood as Greptile, it does raise an interesting question - should the author be the reviewer?
[1] Granted that this is somewhat of a technicality. Devin’s contributions across many orgs are being counted in aggregate here. It would be more accurate to treat “Devin @ Company A” and “Devin @ Company B” as separate entries in this chart.
Should the Author Be The Reviewer?
Most software companies wouldn’t want the PR reviewer to be the same person as the PR author. A large part of why PR reviews happen is to ensure every new piece of code is getting a fresh set of eyes. It seems silly to have Claude Sonnet generate a bunch of code, and then expect Claude Sonnet to find bugs in it.
There are a few counterpoints worth discussing:
Statelessness
If you've used LLM APIs, you'll notice that they are stateless. Every inference call is a clean slate request for intelligence. As a result - asking an LLM to review its own code is looking at it with a fresh set of eyes.
Scaffolding
Scaffolding refers generally to the specific workflows that a tool uses to wrap the LLM call to allow it to do the task at hand. For an AI code reviewer it might be the set of steps it takes to review a diff, checking for bugs, formulating comments, and finally self-assessing comment severity, plus the context retrieval along the way to ensure it's looking at the relevant docs files and other code files in the codebase. For Devin, it likely is just as complex and completely different. In other words, the reviewer is in fact materially different from the author. These are two distinct cars that just happen to have the same engine.
How different are two humans, really?
In a pre-AI world, the author and reviewer of a PR are two distinct people. However, they contain the same intelligence at their core, not unlike two AI tools. Not only do they share a functionally identical brain from a biological standpoint, they even have shared knowledge since they are both trained engineers and shared context since they are coworkers at the same company.
AI-Generated Code Needs Closer Reviewing
AI code isn’t slop, but it is a little sloppy
There is no doubt that AI has made programmers faster and more effective. That said, in my opinion, AI has reduced the average quality of the code that good engineers write. This is not strictly because the models produce worse code than good engineers. It’s because:
- Prompting is an imperfect and lossy way to communicate requirements to AI
- Engineers underestimate the degree to which this is true, and don’t carefully review AI-generated code to the degree to which they would review their own.
The reason for #2 isn’t complacency, one can review code at the speed at which they can think and type, but not at the speed at which an LLM can generate.When you’re typing code, you review-as-you-go, when you AI-generate the code, you don’t.
Interestingly, the inverse is true for mediocre engineers, for whom AI actually improves the quality of the code they produce. AI simply makes good and bad engineers converge on the same median as they rely on it more heavily.
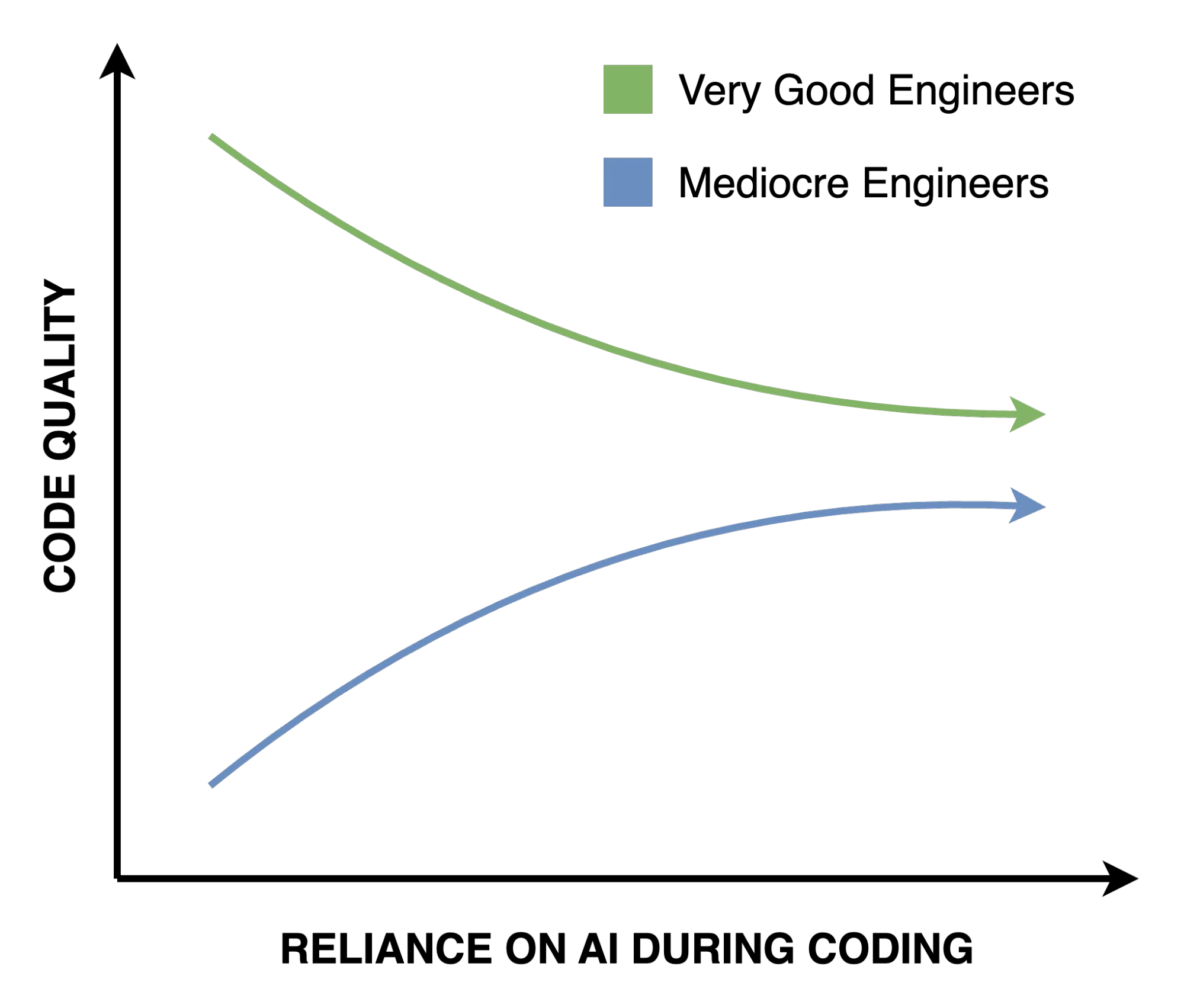
Humans are bad at catching the types of bugs that AI introduces
AI-generated code generally contains more bugs. Moreover, these bugs are not the type humans would introduce. How often have you found a Cursor’s “Apply” function changed a line of code you didn’t expect it would change, and you didn’t notice until later? How many of those bugs were things you could see yourself introducing without AI?
Moreover, PR review is not a great way to catch bugs. Humans just aren’t that good at detecting them, so PR review tends to be more of a style/pattern enforcement exercise, and on occasion an architecture review.
Oddly, it turns out AI is actually much better than humans at finding bugs in code. During our tests, we found the newest Anthropic Sonnet model correctly identified 32 out of the 209 bugs in the “hard” category of our bug finding benchmark. For reference, none of the highly skilled engineers at Greptile could identify more than 5-7.
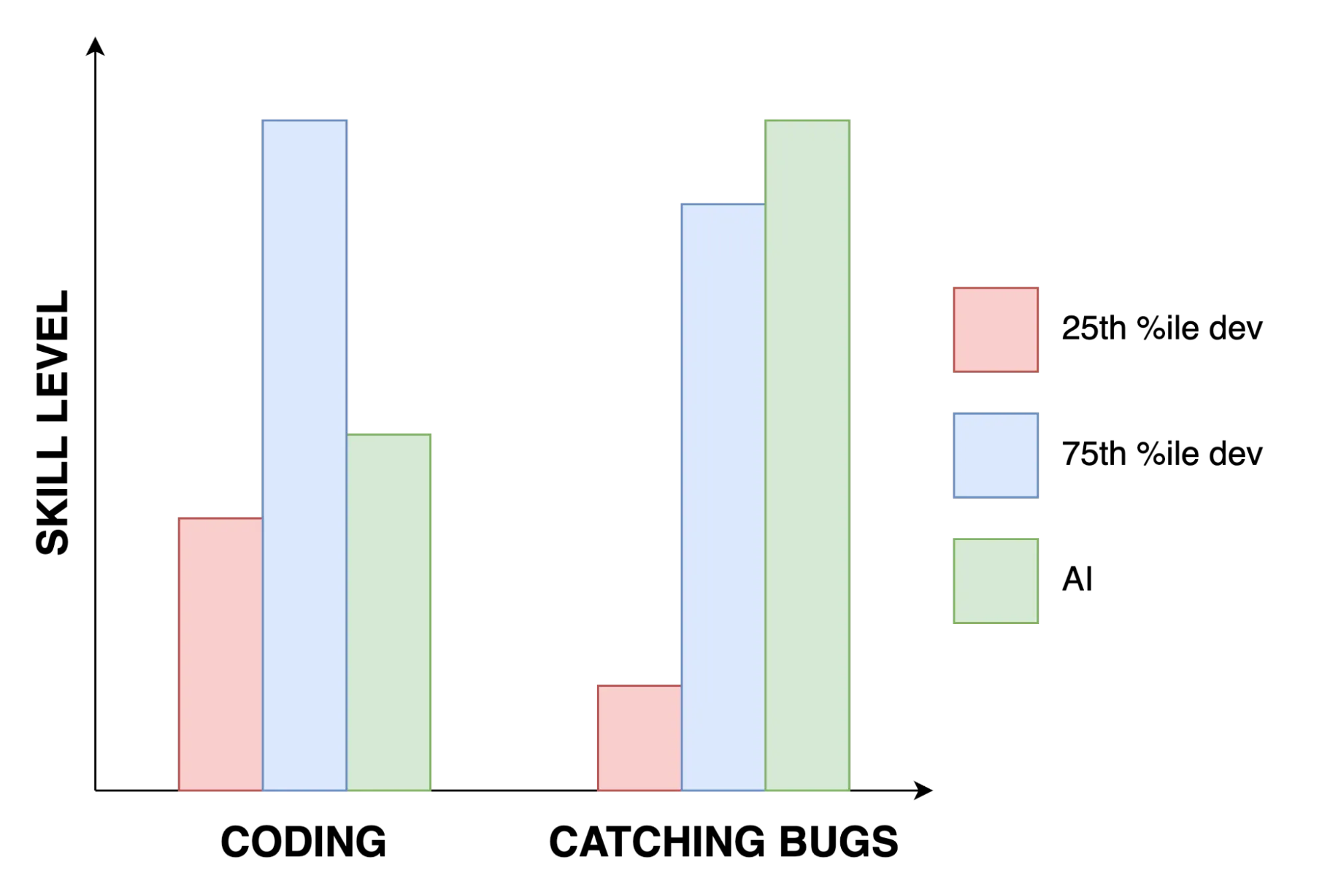
Note that 32/209 isn’t great either, it’s just better than the human developer.
Just In: Used Car Salesman Sincerely Feels You Need A Used Car
Disclaimer in case it wasn’t clear - we sell an AI code reviewer, so take what you will from this. This isn’t an exercise in intellectual dishonesty that exists to persuade you to buy, it’s the earnest attempt at intellectual honesty that led us to work on AI code review in the first place.