Alternative title: Why Greptile Doesn’t Generate Code
Remembering Enron (1985-2001)
I am Daksh - a co-founder of Greptile, the AI code reviewer that catches bugs in pull requests for thousands of software teams.
The month I was born, October 2001, was also the month Enron collapsed. For those unfamiliar, Enron was an energy company founded in 1985. It was one of the most valuable companies in the US public markets at the turn of the century. In 2001, it was discovered that under investor pressure to perform following the inflated expectations of the dot-com bubble, Enron had been hiding billions in debt in off-balance sheet entities.
Arthur Andersen - one of the “Big Five” auditing firms - had audited and approved their books, and had neglected to surface Enron’s accounting fraud.
The most interesting part of this story for me was that AA was more than just Enron’s auditor. They were doing a number of other consulting jobs across the company. In fact, over half of the $50M that Enron was paying them every year was for these consulting jobs, not auditing. This is important and will come up later.
In the following months, three more high-profile scandals were uncovered - Global Crossing, Tyco, and Worldcom collectively lost investors billions of dollars, all engaged in some manner of financial and accounting fraud.
As a result, in the summer of 2002, Congress passed the Sarbanes-Oxley Act (SOX), broadly enforcing the independence of financial auditors from the companies they were auditing. The Act has 11 titles, with Title II being the most interesting.
Title II enforces two things:
- Audits must be performed by external firms, not internal finance/audit teams.
- A company’s audit firm must solely be an auditor for the company. It cannot provide any other services to the company.
The second point there is even more interesting when you consider that not only did Arthur Andersen fail to flag Enron’s accounting fraud, evidence suggested that their consultants had advised Enron’s creation of these debt carrying entities as part of the consulting half of their business.
How should you audit AI-generated code?
In many ways, we view Greptile as an auditor for pull requests. Through some cocktail of human intelligence and a patchwork of AI coding agents, a pull request is born, and Greptile, which is strictly not a coding agent, audits the pull request and surfaces bugs, anti-patterns, and enforces learned best practices.
When we started working on our AI code review bot, one of the most common feature requests we heard was “can Greptile just open a PR to fix the bug that it found?”. Greptile finds bugs in PRs. Naturally users want it to write code to fix those bugs.
We have always politely told the user that this is not, and likely never will be, part of our roadmap. To me, one of our main features is that we don’t generate code. Greptile is not in your IDE or CLI, it’s not an AI software engineer, it’s truly only an AI code reviewer.
To illustrate why this matters, imagine if we built an AI code gen tool - maybe an IDE called “GrepIDE” - alongside an AI code reviewer. There would be two very good questions:
- Can Greptile catch the types of bugs GrepIDE creates? (Capability)
- Will Greptile apply equivalent scrutiny to code produced by ex. Devin and code produced by GrepIDE? (Willingness)
I want to address each of these:
How well would Greptile catch bugs created by the hypothetical “GrepIDE”?
An IDE made by the Greptile team would inevitably have some degree of architectural overlap. While they would not have shared state (one should hope), they might share codebase indexing and retrieval functions. Even if those mechanisms are completely different from each other, the system prompts and agent orchestration would have shared patterns since they were produced by the same company. In essence, these would be products that would be similar enough to make the same mistakes as the other.
The closest parallel I can think of from pre-AI software is the separation of cloud vendors and monitoring vendors. Every major cloud provider has an in-built observability and monitoring solution. Yet, any serious software team will use New Relic/Sentry/Datadog etc.
There are many unrelated reasons here such as the superior DevEx that some of these tools provide, the multi-cloud support etc. A major part of it is the fact that their mistakes are uncorrelated. AWS CloudWatch outages are highly correlated with outages in other AWS services. Datadog doesn’t have flawless uptime, but the outages are generally uncorrelated with AWS outages. There is a lot of value in not having to rely on a service provider’s self reported service status.
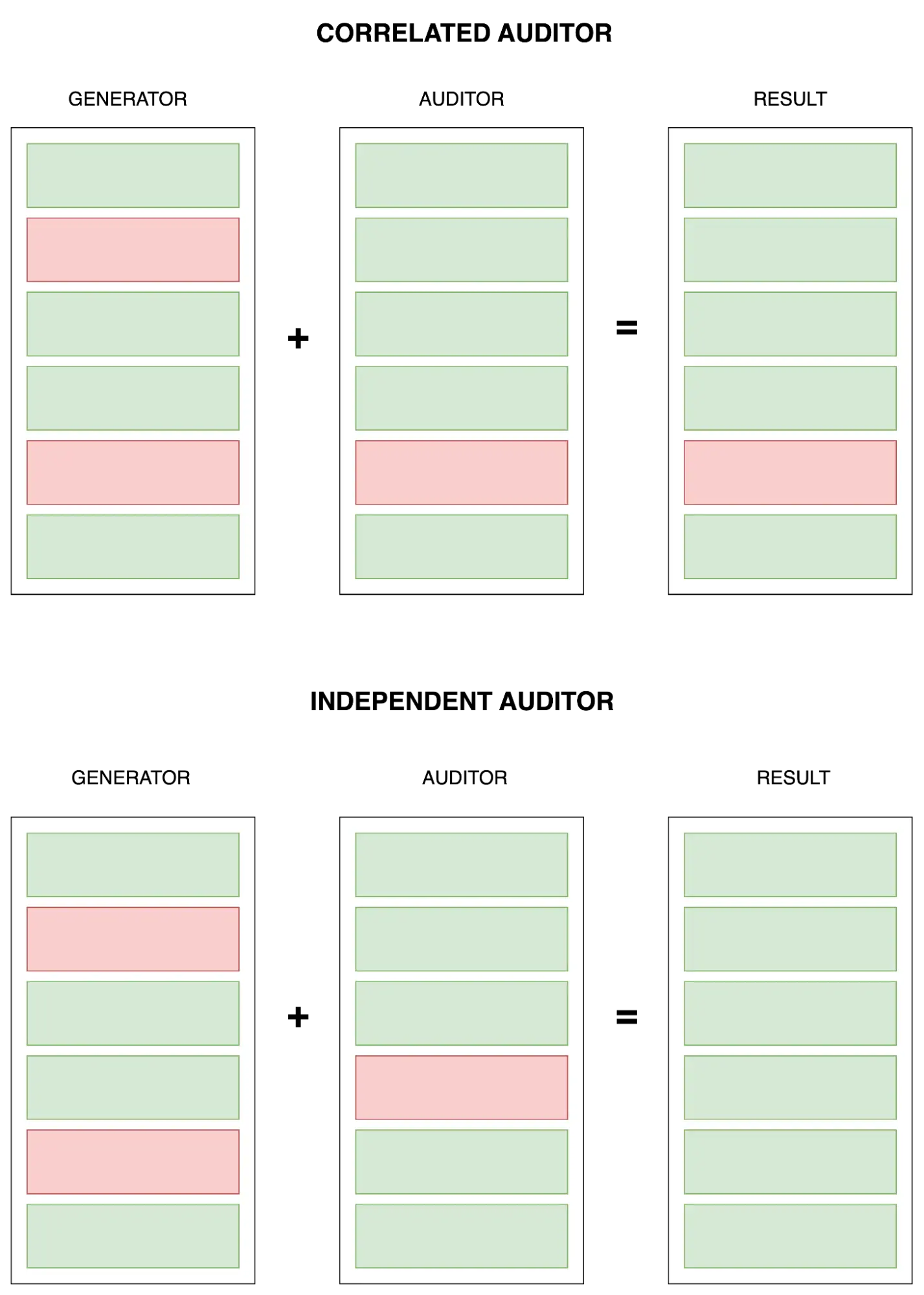
Would Greptile apply the equivalent scrutiny to code produced by ex. Devin vs. the hypothetical GrepIDE?
If we were to produce GrepIDE, like all coding agents, users would evaluate us on the quality and accuracy of the code produced. This criterion is rational, but produces an adverse incentive - to generate code that is perceived to be high quality. High quality code naturally would have fewer PR comments from reviewers, human or AI.
One can already observe the effects of this adverse incentive. Thanks to reinforcement learning through human feedback, LLMs are trained to maximize positive perception. It’s interesting to observe that an LLM might produce dysfunctional garbage, but always include comprehensive comments and error handling to create the appearance of well written code.
As the purveyor of Greptile and GrepIDE, the company would be broadly incentivized to minimize the number of comments that Greptile leaves on GrepIDE code. On the positive side, it would mean GrepIDE would be pushed to produce better code. On the other hand, the team might unconsciously be more forgiving and without meaning to, tune Greptile to be less harsh on GrepIDE code.
As a user, I would not trust Greptile to be a neutral reviewer for GrepIDE-generated code, just like I wouldn’t trust AA to audit Enron’s books when AA had built the entity structure that Enron used to hide their debt.
Who cares?
A long, long time ago, we used to write code one character at a time. Back then, we could read code at least as fast as we could write it. One hundred percent of the code we wrote had passed through our brains and been gut-checked before it was committed.
Moreover, the average engineer was only writing a pull request or two a week - and while review was often a bottleneck, overall it was manageable.
Over the last two years, both of these things have changed. We now generate code far faster than we can read it. An increasingly large percentage of committed code was never read by a human person pre-commit.
Additionally, we’re now producing too many pull requests, and review is certainly a bottleneck, if it wasn’t already.

These posts are just a few months apart.
Coding agents are dumb in novel ways
It’s no secret that the code produced by these coding agents isn’t perfect. What’s interesting is that the bugs it produces are different from the ones humans produce and therefore know to look for.
Some examples of bugs I have seen coding agents write that I can’t imagine a human to write:
- Calling plausible-sounding but completely made up functions
- Hallucinating imports
- Hard-coding values that clearly should not be hardcoded - like some timeouts
Another folly of coding agents is something I like to call “collateral damage” - when long-running agents change a random line in an unrelated file, often going unnoticed by the programmer. I could not imagine a human developer accidentally doing that.
While the agents are getting better with time, programmers are lazy, and will always push them slightly farther than they can reasonably go.

Software needs an independent auditor
If your company is using AI to generate code, it might be a good idea to have an AI tool to review it. The review tool should likely also be independent of the generating tool.
The argument for it is simple:
- AI-generated code will continue to be buggy even as models get better
- The AI coding agent will require an independent, adversarial agent to check its output
- The adversarial agent will need to live in the pull request step to ensure it is run at every code change, no matter how the code was produced.

Some helpful links:
- Wait - isn't it still the same model reviewing the code even if it's different products? I discuss this here: Do AI Code Reviewers Conflict with AI Code Generators?
- Nice paper about evaluating LLMs using LLMs: https://dl.acm.org/doi/abs/10.1145/3654777.3676450
Random fact: Not only was I born in the same month that Enron collapsed, I was born less than 20 minutes from the Enron HQ in Houston TX.