I'm Daksh, one of the co-founders of Greptile. At Greptile, our goal is to build the agents that can autonomously validate code. Our first step toward that goal is to build a really great code reviewer for merge requests.
Recently, we rolled out v3, a complete rewrite of our code review workflow. In this post, I'm going to go into some detail around how v3 works.
Performance results
Now that v3 has reviewed over 1B lines of code since launch, we have comprehensive data to show v3 is far better than v2 along every useful axis.
| Metric | v2 | v3 | % Change |
|---|---|---|---|
| Upvote/Downvote Ratio | 1.44 | 5.13 | +256% |
| Upvotes per 10K Comments | 109 | 183 | +68% |
| Action Rate (%) | 34.75 | 59.24 | +70.5% |
Limitations of v2
To understand what makes v3 work so much better than v2, we must first understand how v2 worked.
Crudely, v2 was a flowchart as shown in this image. The workflow receives the PR diff and metadata, has a well-defined codebase context step, and then a well-defined external context step. Lastly, it produces review comments.
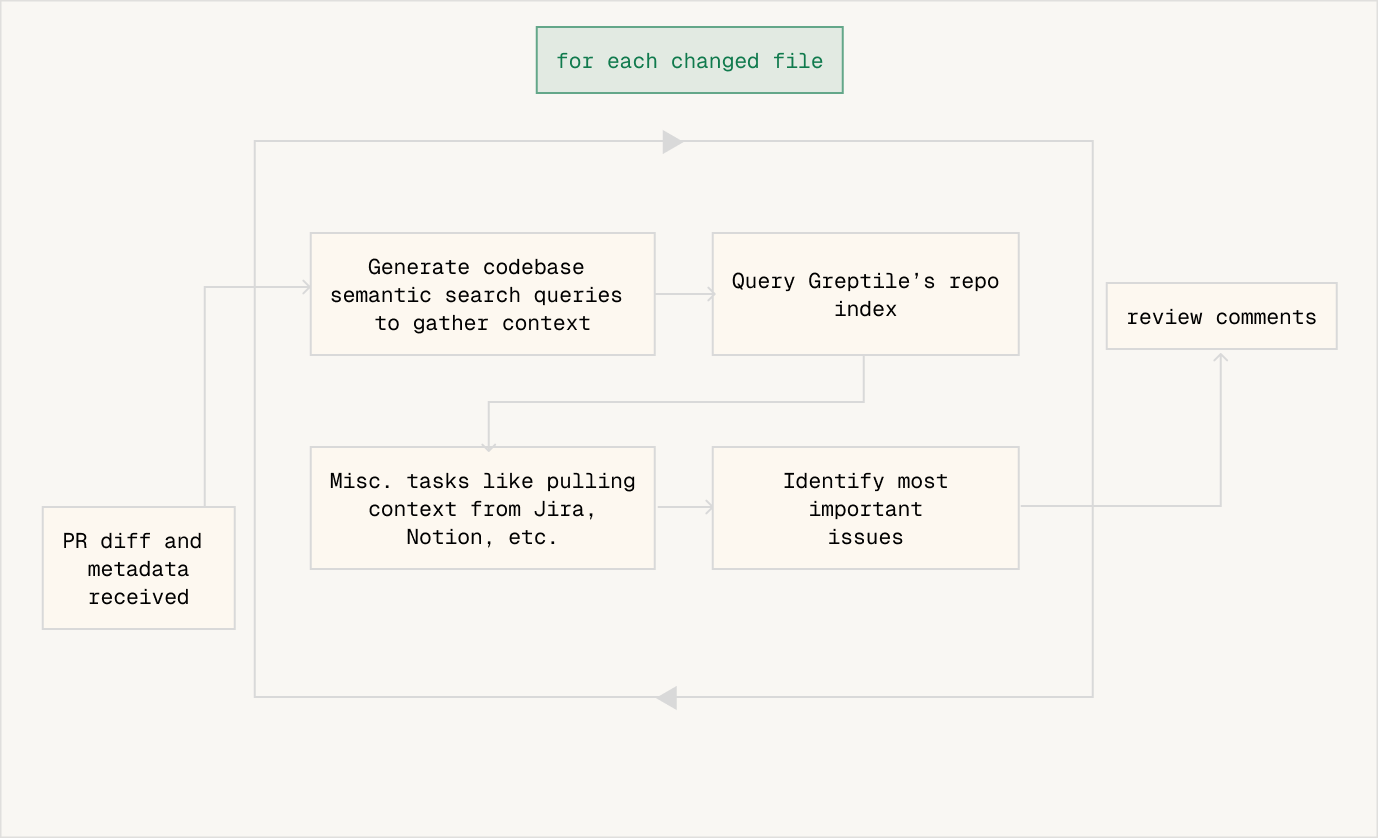
For last-gen LLMs from GPT-4 to Claude 3.5 Sonnet, this was the most powerful way to use LLMs. Give them a series of well-defined tasks. For some of the tasks, provide data from an external source as needed.
There is an obvious limitation here, among others. The rigidity of the flowchart prevents the system from using new information that it gets from the search step. Here's an example to illustrate why this is a problem:
- System is reviewing a file changing the login button
onClickaction - System uses codebase search to find the file where the
onClickfunction is defined - Turns out the
onClickfunction calls a function in a third file - System will never see that third file, it's moving on to the next step in the flowchart
A "detective" approach to code review
In v3, we introduced a new approach to code review. We let the system run in a loop, with access to some key tools such as codebase search and accessing learned rules. The system has a very high limit on how many times it can run LLM inference or access tools, so it can continue recursively searching the codebase to follow nested function calls and do multi-hop "thinking".
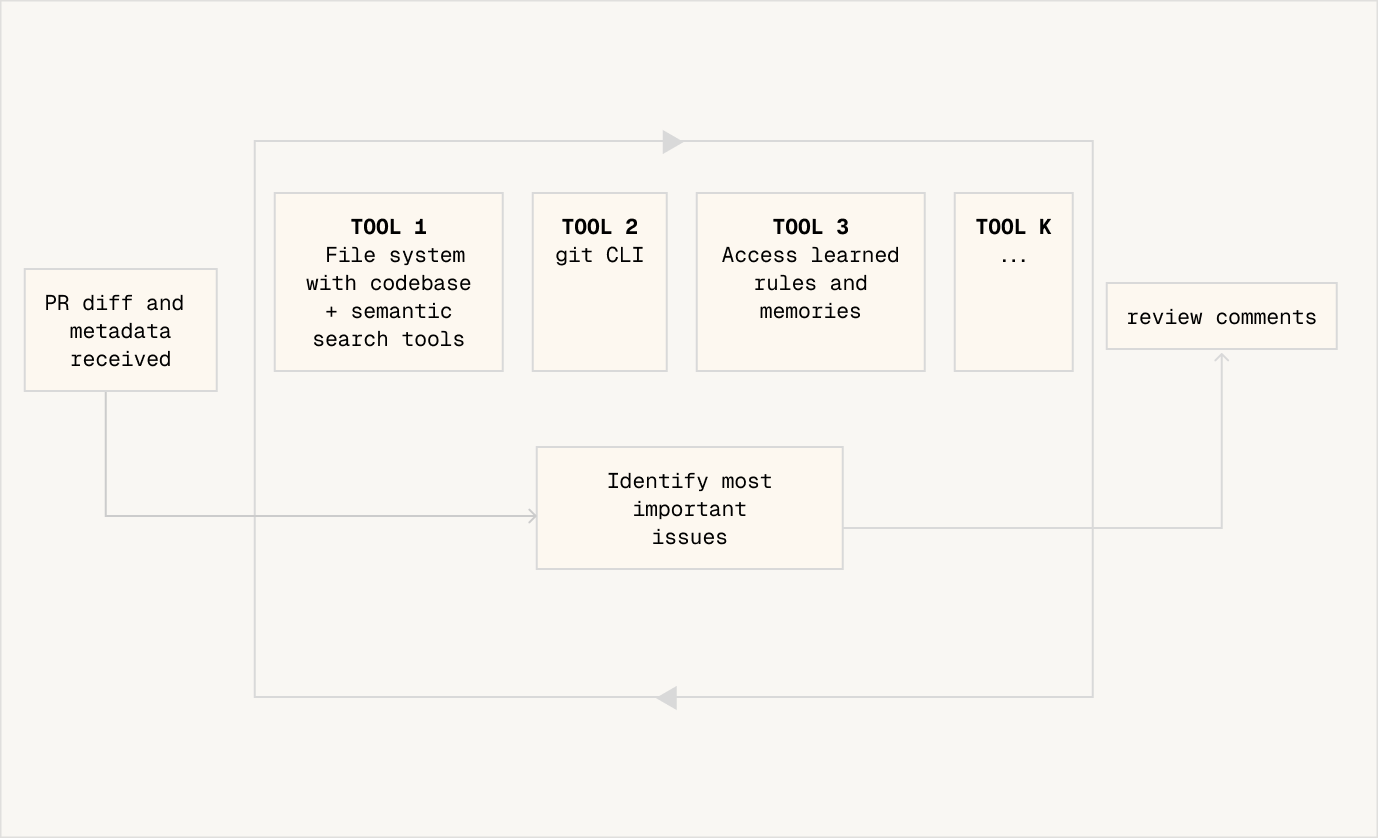
Let's take an example of how this works.
- Consider a PR in which a developer updates
calculateInvoiceTotal()to handle discounts differently. - Greptile's agent expands beyond the diff and searches the entire codebase for similar logic. It finds three related implementations, including a nested call path inside
generateMonthlyStatement(). - In that deeper chain, it spots something off:
applyProration()still uses the old discount formula. - The agent checks git history and discovers this helper was created during an old hotfix and never refactored.
- With the pattern mismatch + stale logic + historical context, Greptile raises a targeted comment: "This nested call still uses the previous discount rules; updating it will prevent inconsistent totals across invoices and statements."
The performance improvements are quite significant. The obvious one is greater accuracy. Naturally, with ways to do long-running explorations of the diffs and the codebase, v3 simply catches more bugs.
A second, emergent effect is that higher precision, or in other words, a higher signal-to-noise ratio. Based on our study, the reason for this is likely an increased threshold for "sureness" since v3 can challenge its own hypothesis more strongly. Naturally, this means lower confidence comments can be safely eliminated. The acceptance rate for v3 is 70.5% higher than v2.
As a side bonus, v3 uses caching far more effectively. In spite of using more context tokens than v2 (around 3 times more), it actually has 75% lower inference costs for our self-hosted customers, thanks to extremely high cache hit rates.